Desktop only
Please visit this site on a desktop or laptop.
Desktop only
Please visit this site on a desktop or laptop.
AI performance plateaus when training data doesn't cover your domain deep grammar. Synth generates the data to break through.
Industry standards, operational procedures, tacit organizational knowledge: none of this exists in public crawls. No frontier model was trained on it. And in multilingual, sector-specific contexts, the gap only widens.

When models direct their own processes, error tolerance drops to near zero. Industrial use cases demand 0–2% error rates and synthetic data is the most efficient way to make your agents accurately reason in your domain, in your language, against your standards, fully integrated into your workflow.
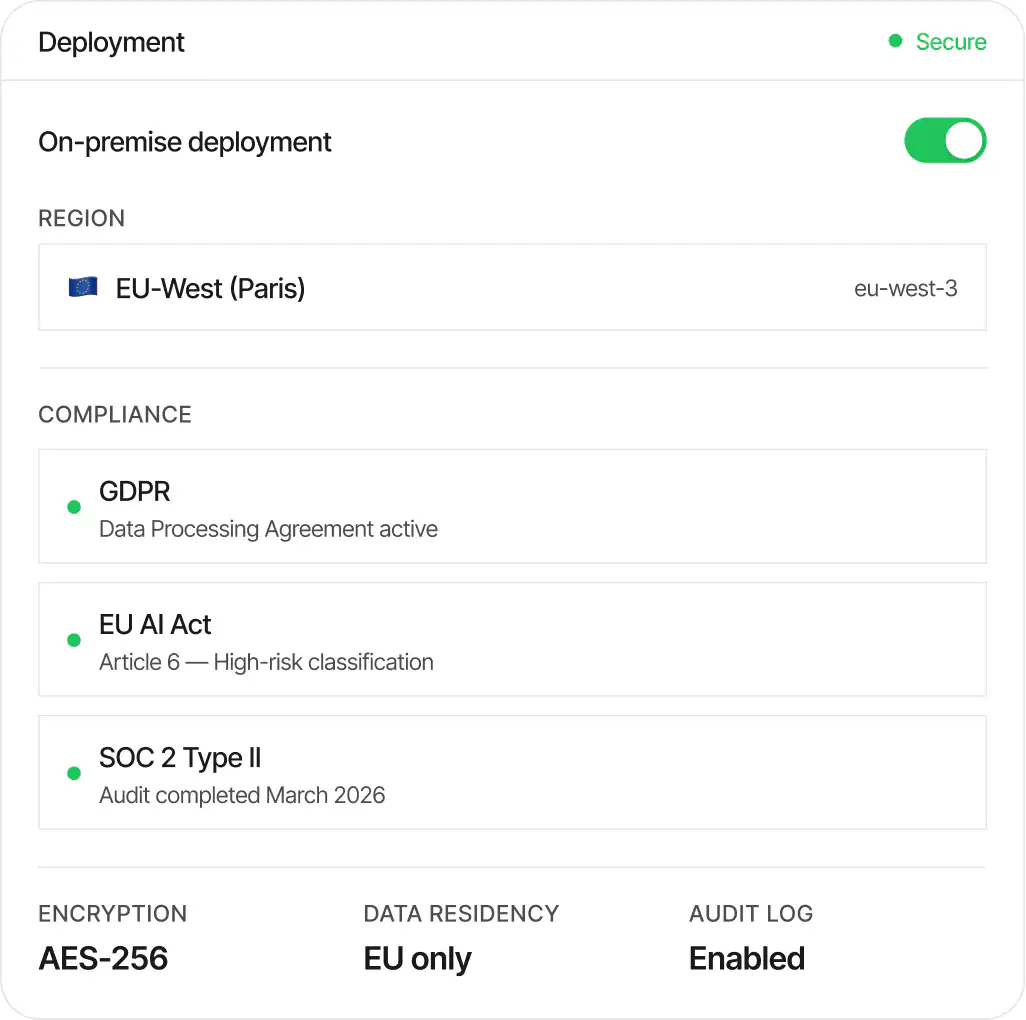
High-risk, high-value AI applications require full auditability and control over training pipelines. You need on-premise capability, data residency, and a pipeline you can prove compliant.
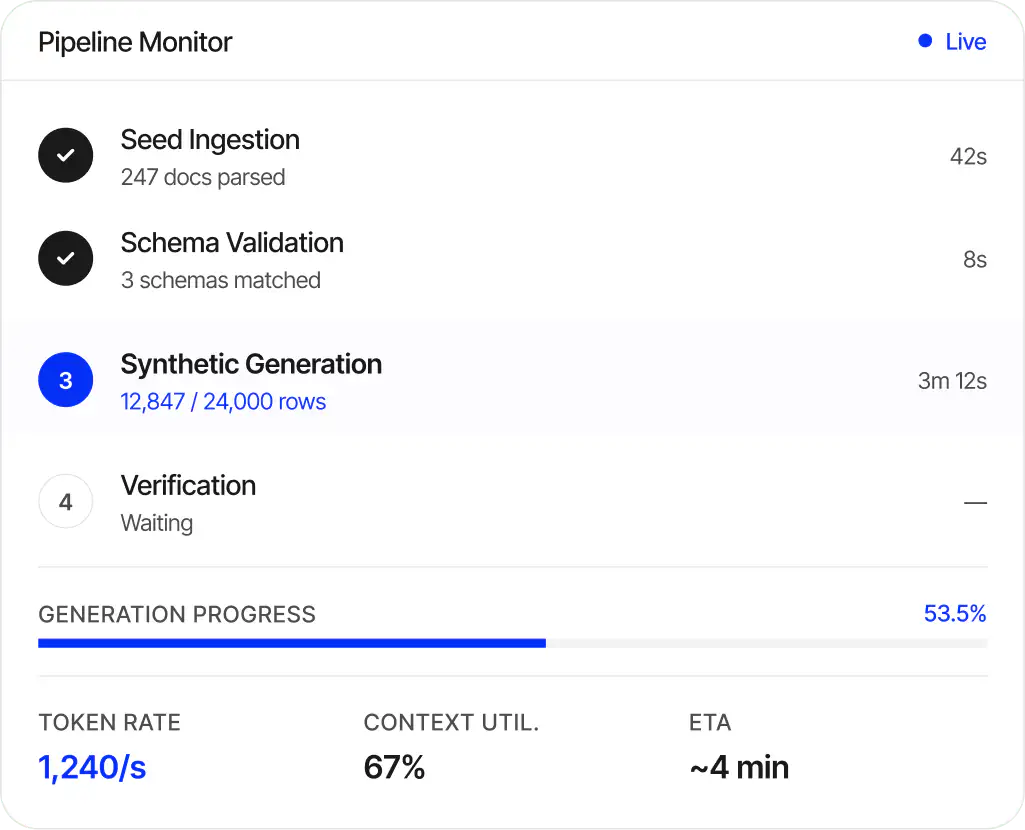
No visibility into what's being generated, which models are running, or whether schemas are matched. You can't trust what you can't observe. You can't audit what you can't trace.
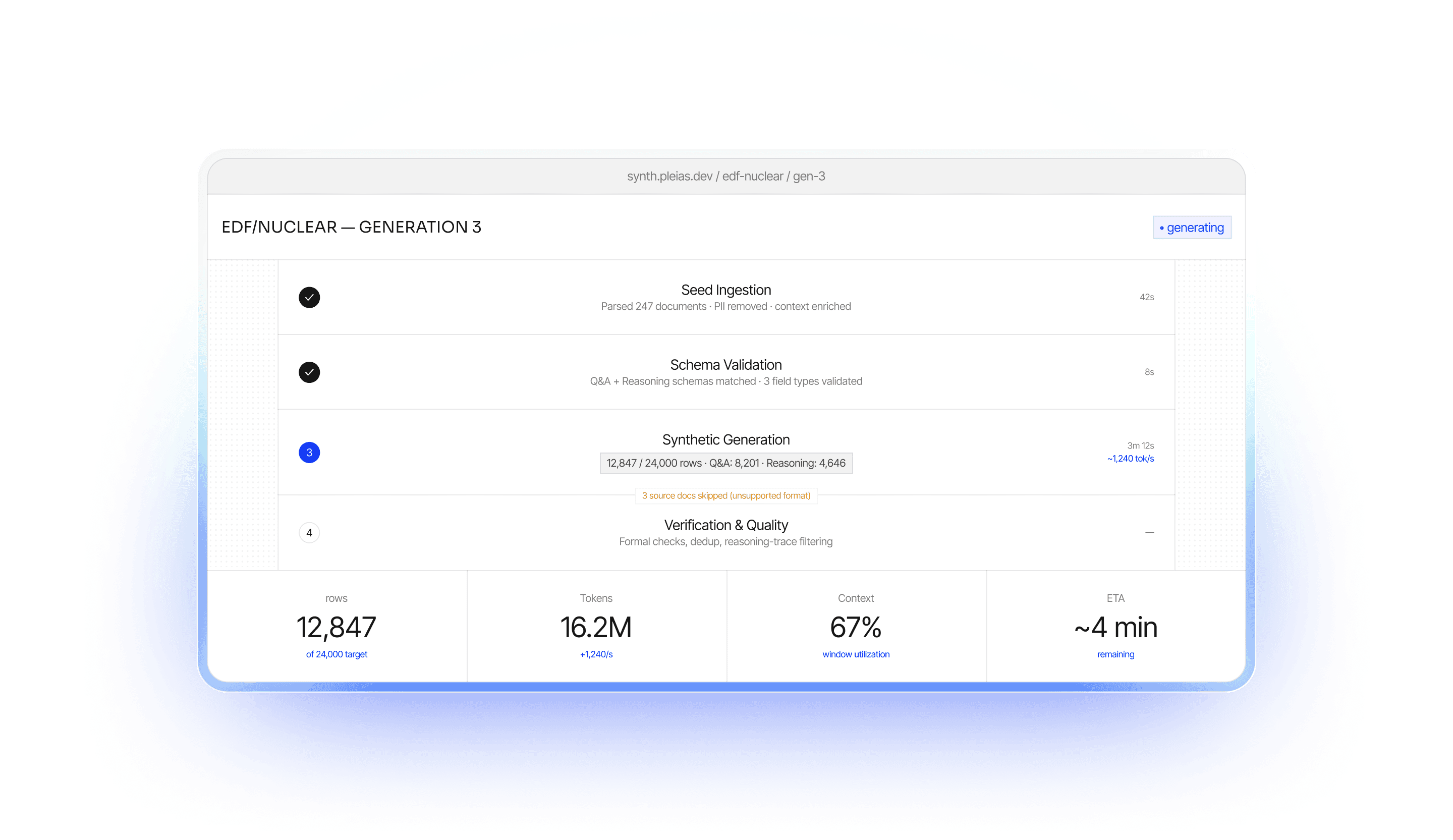
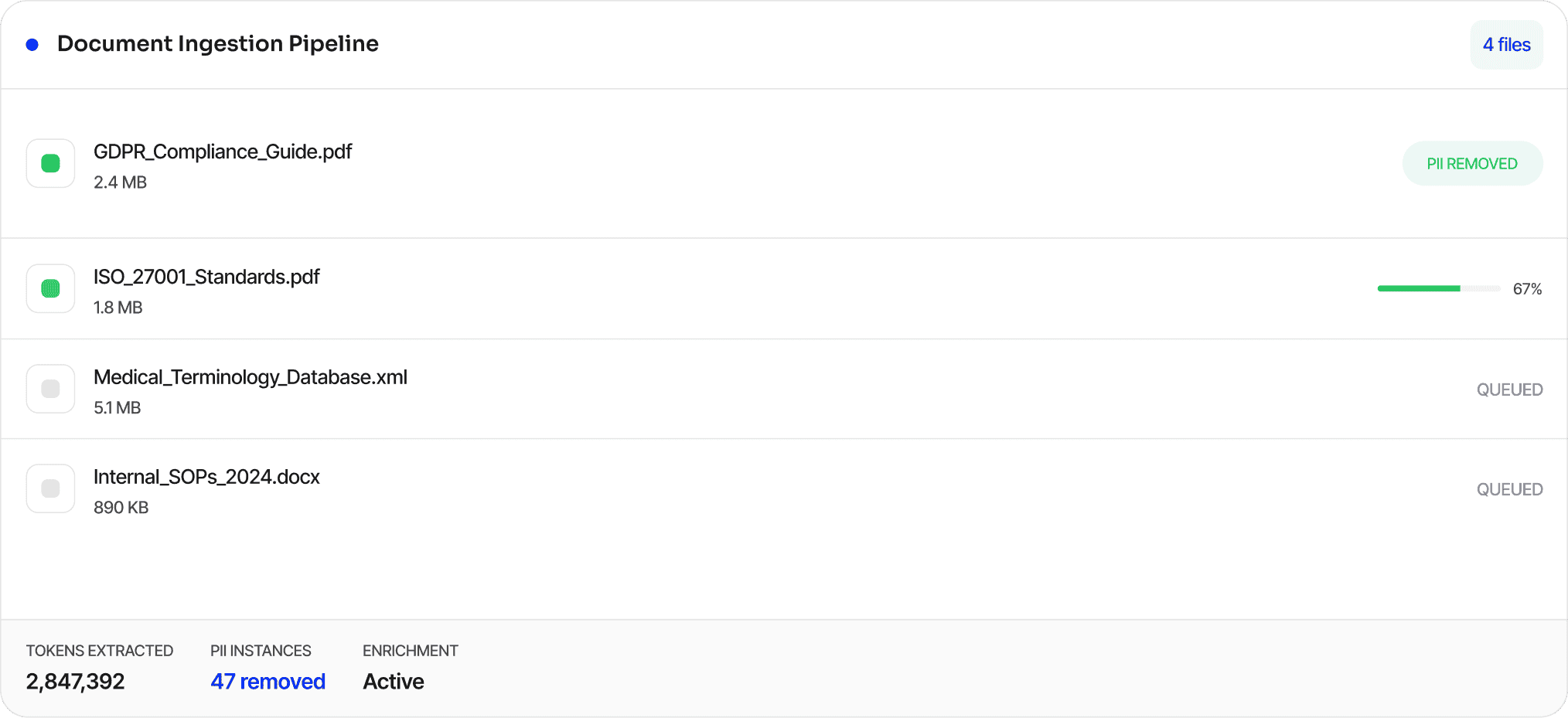
Three steps. Full observability at every stage. Your domain expertise becomes frontier-grade synthetic training data.

Upload your domain documents — complex unstructured (PDFs, Word, XML…) and structured data. Synth parses, removes PII, and enriches context automatically.

Bespoke generator models produce structured synthetic data at scale — Q&A pairs, reasoning chains, memorization sets, multilingual data — with schema validation at every step.
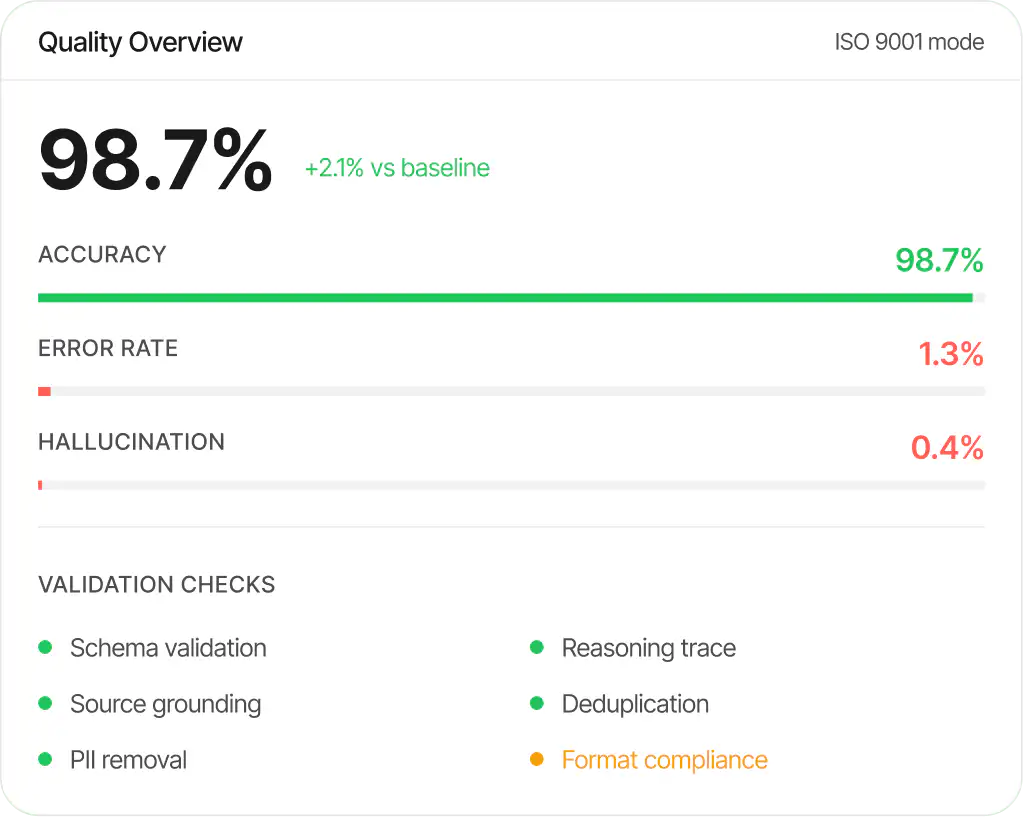
Formal checks, reasoning-trace filtering, and LLM-based curation ensure quality. Output drives beyond state-of-the-art training efficiency.
Synth datasets consistently produce state-of-the-art model performance across generalist reasoning and domain benchmarks.
Industry-specialised models surpassing performance of 20x larger ones
More data efficient training compared to leading training mixes
Average gain in specialised industry benchmarks
| Benchmark | SYNTH | Qwen3 | Score per 1T tokens | Efficiency |
|---|---|---|---|---|
| TruthfulQA | 17.6 | 9.7 | 117.3 0.27 | 435× |
| TriviaQA | 17.6 | 13.4 | 117.3 0.37 | 315× |
| MMLU | 46.6 | 52.3 | 310.7 1.45 | 214× |
| GPQA Diamond | 31.4 | 24.4 | 209.3 0.68 | 309× |
| XFinBench | 59.1 | 58.4 | 394.0 1.62 | 243× |
| ESGenius | 63.2 | 57.6 | 421.3 1.60 | 263× |
| MMLU-Pro | 16.7 | 31.9 | 111.3 0.89 | 126× |
Full observability, inspectable outputs, and sovereign deployment. No black boxes.
See every step in real time. Token generation rates, model health, schema validation, context utilization. Know exactly what's happening.
Deploy on-premise within your infrastructure. GDPR and EU AI Act compliant. Your data never leaves your control.
Browse generated data directly in the UI. Quality metrics, sample previews, and distribution breakdowns — no code needed.
Integrate SYNTH into your AI pipeline. Start generating domain-specific synthetic datasets in minutes with pay-as-you-go pricing.
Wherever domain knowledge, data sovereignty, and operational accuracy are the baseline for AI.
Training ultra-efficient agentic models for deployment on edge and at scale
Medical reasoning and patient support for spine care, grounded in clinical literature and practioners best practices
Complex psychometric reasoning and real-time distress detection for Paris public transport, where a SYNTH-trained sub-1B model outperforms frontier closed models.
Pleias builds open knowledge infrastructure for frontier AI, with peer-reviewed research and institutional recognition.
France's most prestigious Deep Tech competition, recognizing breakthrough AI research.
Nvidia and pleias released the the first massive open synthetic dataset for personas in Europe: Nemotron-Personas-France
Backed by German Federal Agency for Disruptive Innovation
Join the beta to generate domain-specific training data at scale.
Available as API or on-premise deployment.

